E-commerce Multi-modal Text2Image Retrieval Challenge

目录
1. 赛事简介
1.1. 训练集数据组织形式
train_imgs.tsv:图片库
# 组织形式:{商品图片id} + \t + {图片base64编码内容}
1000002 /9j/4AAQSkZJ...YQj7314oA//2Q==
1000016 /9j/4AAQSkZJ...SSkHcOnegD/2Q==
1000033 /9j/4AAQSkZJ...FhRRRWx4p//2Q==
train_texts.jsonl:文本库
{"query_id": 8426, "query_text": "胖妹妹松紧腰长裤", "item_ids": [42967]}
{"query_id": 8427, "query_text": "大码长款棉麻女衬衫", "item_ids": [63397]}
{"query_id": 8428, "query_text": "高级感托特包斜挎", "item_ids": [1076345, 517602]}
1.2. 任务目标
以Recall@1/5/10的平均值(MeanRecall)作为该任务主指标,即所预测的 TOP-1/5/10 预测结果包含目标图像。
2. CLIP
2.1. 背景与动机
- 之前 CV 领域的模型依赖高质量的人工标注数据,而 CLIP 模型能够直接从网络规模的数据中学习。
- CLIP 简化了 ConVIRT 模型架构,同时扩大了训练数据的规模(4 亿个图文对)。
2.2. 方法
- 选择对比学习(contrastive representation learning)的方法来预训练模型。
- CLIP 只预测图像与哪一整个文本的整体配对,而不关注文本中确切的单词。
- 对比学习相较于传统与 Transformer 模型有更高的效率,且 zero-shot 迁移到其他任务的效率更高。
- 由于过拟合不是 CLIP 模型需要解决的主要问题,所以 CLIP 简化了 ConVIRT 模型架构,并从头训练 CLIP 模型。
- 在文本编码器中使用掩码自注意(Masked self-attention)是未来工作的一个方向(CLIP 应该是没有对文本编码器进行掩码的)。
- CLIP 的性能对文本编码器的敏感度较低。
2.3. 分析
- 与表征学习相反(representation learning capability),CLIP 通过研究零样本迁移能力(zero-shot transfer)来评估模型的任务学习能力(task-learning capabilities)。
- CLIP 最佳的视觉编码器是 ViT-L/14@336px。(在 Chinese CLIP中,我们使用的是 ViT-H/14@224px,其拥有最佳的性能)
2.4. 模型架构
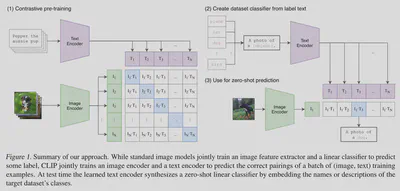
CLIP 是文本图像多模态模型,主要结构包含两个编码器:文本编码器与图像编码器,训练流程如下所示。
步骤一:假设一个 batch 包含了 $n$ 个 文本-图像对,先提取每种模态数据的特征表示。有表达式
$$ \begin{align} &I_f = \mathsf{ImageEncoder}(I) \\ &T_f = \mathsf{TextEncoder}(T) \end{align} $$其中,$I$ 为图像输入矩阵,维度为 $[n, h, w, c]$,$h$ 和 $w$ 分别为图片的高与宽(以像素为单位),$c$ 为图像的色彩通道数;
$T$ 为文本输入矩阵,维度为 $[n, l]$,$l$ 为词向量长度;
$I_f$ 为图像编码矩阵,维度为 $[n, d_i]$,$d_i$ 为图像编码器的输出向量维度;
$T_f$ 为文本编码矩阵,维度为 $[n, d_t]$,$d_t$ 为文本编码器的输出向量维度。
即,图像编码器 $\mathsf{ImageEncoder}$ 将维度为 $[1, h, w, c]$ 的矩阵映射为了 $[1, d_i]$ 的向量,文本编码器 $\mathsf{TextEncoder}$ 将维度为 $[1, l]$ 的矩阵映射为了 $[1, d_t]$ 的向量。
步骤二:为了计算每个 文本-图像对 的编码向量之间的余弦相似性,需要统一编码向量的维度并作归一化处理。有表达式
$$ \begin{align} &I_{embed} = \mathsf{Normalize}((I_f * W_i), axis=1) \\ &T_{embed} = \mathsf{Normalize}((T_f * W_t), axis=1) \\ &logits = I_{embed} * T_{embed}' * e^t \end{align} $$其中,$W_i$ 为可学习的权重矩阵,维度为 $[d_i, d_e]$;$W_t$ 为可学习的权重矩阵,维度为 $[d_t, d_e]$;$I_{embed}$ 与 $T_{embed}$ 都为维度为 $[n, d_e]$ 的联合多模态嵌入向量;$logits$ 为缩放后的向量余弦相似性;$t$ 为可学习的权重,$axis$ 表示对列进行归一化。
步骤三:计算对称损失函数(symmetric loss function)。有表达式
$$ \begin{align} &labels = \mathsf{Arange}(n) \\ &l_i = \mathsf{CrossEntropyLoss}(logits, labels, axis=0) \\ &l_t = \mathsf{CrossEntropyLoss}(logits, labels, axis=1) \\ &l = (l_i + l_t)/2 \end{align} $$其中,$labels$ 是维度为 $n$ 的对角单位矩阵。交叉熵损失函数 $\mathsf{CrossEntropyLoss} = -\frac{1}{N} \sum_i \sum_{c=1}^{M}y_{ic} \cdot log(p_{ic})$,其中 $N$ 是样本数量;$M$ 是类别的数量;$y_{ic}$ 是符号函数( 0 或 1 ),如果样本 $i$ 的真实类别等于 $c$ 取 1 ,否则取 0;$p_{ic}$ 是观测样本 $i$ 属于类别 $c$ 的预测概率。
3. Chinese CLIP
3.1. 模型框架
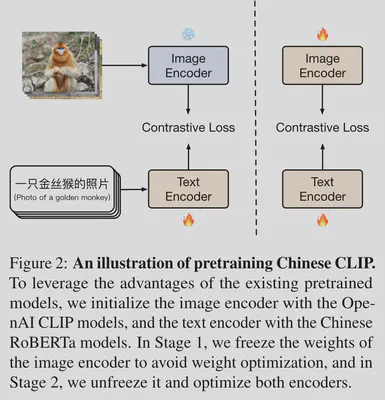
Chinese ClIP 在模型框架上与 CLIP 并无差别,只不过在训练过程中使用了 Locked-image Tuning(LiT)策略【1】。
在训练的第一阶段:直接使用原始 CLIP 模型已经训练好的图像编码器并冻结参数,文本编码器来自 RoBERTa-wwm-Chinese【2】并在训练过程中不断更新权重直到损失函数降到一定程度。
在训练的第二阶段:解冻图像编码器, 同步训练图像编码器与文本编码器直到损失函数降到一定程度。
3.2. 训练细节与结果
Chinese-CLIP 在 MUGE-Retrieval 数据集(即此次比赛所使用的数据集)进行了测试,验证集结果为:
“mean_recall”: 83.6,
“r1”: 68.9,
“r5”: 88.7,
“r10”: 93.1
4. 实验结果
4.1. 基线
模型参数(点击查看)
aggregate: True
batch_size: 256bert_weight_path: None
beta1: 0.9
beta2: 0.98
checkpoint_path: /raid/ljh/home/game/experiments/256batch_3epoch/checkpoints
clip_weight_path: None
context_length: 60
debug: False
device: cuda:0
distllation: False
eps: 1e-06
freeze_vision: False
gather_with_grad: False
grad_checkpointing: True
kd_loss_weight: 0.5
local_device_rank: 0
log_interval: 1
log_level: 20
log_path: /raid/ljh/home/game/experiments/256batch_3epoch/out_2024-06-08-05-42-02.log
logs: /raid/ljh/home/game/experiments/
lr: 2e-05
mask_ratio: 0.0
max_epochs: 3
max_steps: 381
name: 256batch_3epoch
num_workers: 4
precision: amp
rank: 0
report_training_batch_acc: True
reset_data_offset: True
reset_optimizer: True
resume: /raid/ljh/home/game/pretrained_weights/clip_cn_vit-h-14.pt
save_epoch_frequency: 1
save_step_frequency: 999999
seed: 123
skip_aggregate: False
skip_scheduler: False
teacher_model_name: None
text_model: RoBERTa-wwm-ext-large-chinese
train_data: /raid/ljh/home/game/datasets/normalization_data/lmdb/train
use_augment: True
use_bn_sync: False
use_flash_attention: False
val_data: /raid/ljh/home/game/datasets/processed_data/lmdb/valid
valid_batch_size: 256
valid_epoch_interval: 1
valid_num_workers: 1
valid_step_interval: 999999
vision_model: ViT-H-14
warmup: 200
wd: 0.001
world_size: 8
结果:
| epoch = 1 | 2 | 3 | |
|---|---|---|---|
| valid_mean_recall | 82.8142 | 83.0471 | 83.5130 |
| test_mean_recall | N/A | N/A | 82.6539 |
epoch = 3 时模型在 valid 上有最好的结果(由于设置的 max_epoch=3,模型最好结果正在做进一步测试):
“mean_recall”: 83.51304579339724,
“r1”: 69.00958466453673,
“r5”: 88.59824281150159,
“r10”: 92.93130990415335
4.2. 随机掩码
4.2.1. 图像掩码率为 0.1
模型参数(点击查看)
aggregate: True
batch_size: 256
bert_weight_path: None
beta1: 0.9
beta2: 0.98
checkpoint_path: /raid/ljh/home/game/experiments/256batch_6epoch_mask_img_10/checkpoints
clip_weight_path: None
context_length: 60
debug: False
device: cuda:0
distllation: False
eps: 1e-06
freeze_vision: False
gather_with_grad: False
grad_checkpointing: True
kd_loss_weight: 0.5
local_device_rank: 0
log_interval: 1
log_level: 20
log_path: /raid/ljh/home/game/experiments/256batch_6epoch_mask_img_10/out_2024-06-08-13-25-09.log
logs: /raid/ljh/home/game/experiments/
lr: 2e-05
mask_ratio: 0.1
max_epochs: 6
max_steps: 762
name: 256batch_6epoch_mask_img_10
num_workers: 4
precision: amp
rank: 0
report_training_batch_acc: True
reset_data_offset: True
reset_optimizer: True
resume: /raid/ljh/home/game/pretrained_weights/clip_cn_vit-h-14.pt
save_epoch_frequency: 1
save_step_frequency: 999999
seed: 123
skip_aggregate: False
skip_scheduler: False
teacher_model_name: None
text_model: RoBERTa-wwm-ext-large-chinese
train_data: /raid/ljh/home/game/datasets/normalization_data/lmdb/train
use_augment: True
use_bn_sync: False
use_flash_attention: False
val_data: /raid/ljh/home/game/datasets/processed_data/lmdb/valid
valid_batch_size: 256
valid_epoch_interval: 1
valid_num_workers: 1
valid_step_interval: 999999
vision_model: ViT-H-14
warmup: 200
wd: 0.001
world_size: 8
结果:
| epoch = 1 | 3 | 4 | |
|---|---|---|---|
| valid_mean_recall | 82.7742 | 83.1936 | 83.1936 |
| test_mean_recall | N/A | N/A | N/A |
4.2.2. 图像掩码率为 0.4
模型参数(点击查看)
aggregate: True
batch_size: 256
bert_weight_path: None
beta1: 0.9
beta2: 0.98
checkpoint_path: /raid/ljh/home/game/experiments/256batch_20epoch_mask_only_img40/checkpoints
clip_weight_path: None
context_length: 60
debug: False
device: cuda:0
distllation: False
eps: 1e-06
freeze_vision: False
gather_with_grad: False
grad_checkpointing: True
kd_loss_weight: 0.5
local_device_rank: 0
log_interval: 1
log_level: 20
log_path: /raid/ljh/home/game/experiments/256batch_20epoch_mask_only_img40/out_2024-06-07-08-36-13.log
logs: /raid/ljh/home/game/experiments/
lr: 2e-05
mask_ratio: 0.4
max_epochs: 20
max_steps: 5080
name: 256batch_20epoch_mask_only_img40
num_workers: 4
precision: amp
rank: 0
report_training_batch_acc: True
reset_data_offset: True
reset_optimizer: True
resume: /raid/ljh/home/game/pretrained_weights/clip_cn_vit-h-14.pt
save_epoch_frequency: 1
save_step_frequency: 999999
seed: 123
skip_aggregate: False
skip_scheduler: False
teacher_model_name: None
text_model: RoBERTa-wwm-ext-large-chinese
train_data: /raid/ljh/home/game/datasets/normalization_data/lmdb/train
use_augment: True
use_bn_sync: False
use_flash_attention: False
val_data: /raid/ljh/home/game/datasets/processed_data/lmdb/valid
valid_batch_size: 256
valid_epoch_interval: 1
valid_num_workers: 1
valid_step_interval: 999999
vision_model: ViT-H-14
warmup: 400
wd: 0.001
world_size: 4
结果:
| epoch = 1 | 2 | 3 | 6 | 10 | 19 | |
|---|---|---|---|---|---|---|
| valid_mean_recall | 82.5146 | 82.3616 | 81.7226 | 80.4712 | 80.5777 | 80.3714 |
| test_mean_recall | 82.0477 | N/A | N/A | N/A | N/A | N/A |
5. 当前打榜结果
排行榜
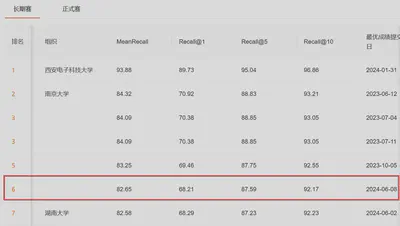
最佳测试集结果

6. 参考文献
【1】Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. 2022. Lit: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18123–18133.
【2】Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Shijin Wang, and Guoping Hu. 2020. Revisiting pre-trained models for Chinese natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, pages 657–668, Online. Association for Computational Linguistics.
【3】Hao X, Zhu Y, Appalaraju S, et al. Mixgen: A new multi-modal data augmentation[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023: 379-389.