具身智能 (Embodied AI) 调研报告
1. Embodied AI 领域活跃的组织
- Google 公司 - Google DeepMind
- 斯坦福大学 - Robotics and Embodied Artificial Intelligence Lab (REAL)
- 斯坦福大学 - Stanford Vision and Learning Lab (SVL)
以下研究上述三个组织或多或少都参与其中。
附:
- 视觉领域比较活跃的大学有 The University of Michigan
2. Embodied AI 领域模型的发展脉络
2.1. 《RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE》- 2023
项目网址:https://robotics-transformer1.github.io/
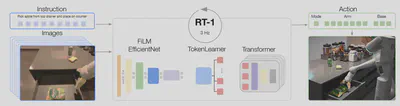
RT-1 模型接受文本指令和 6 张图片记录(a history of 6 images)作为输入,输出机器人的运动信息,包括:机械臂的运动信息(x, y, z, roll, pitch, yaw, opening of the gripper),其中 [x, y, z] 表示机械臂末端在三维空间中的坐标,[roll, pitch, yaw] 表示机械臂末端的空间姿态,[opening of the gripper] 表示机械臂末端爪钳的开合状态;机器人基座的信息(x, y, yaw),其中 [x, y] 表示基座的位置坐标,[yaw] 表示机器人的朝向方向;和一个模块控制信息[mode],该信息用来控制机器人在控制手臂、底座、终止任务这三个状态之间进行切换。(有关于 roll, pitch, yaw 的介绍见附录)
为了提高效率,RT-1 使用了 Token-Learner (《TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?》)来对输入到 Transformer 解码器的 tokens 进行软选择,减小模型的计算量。
缺点:RT-1 采用模仿学习,这表明 RT-1 无法完成数据分布之外的动作或者任务,即没有泛化能力。
数据来源:自我采集
评估方式:在真实世界的随机场景,机器人训练场所以及两个新的办公室厨房环境中总共进行了 3000 多次评估测试。
2.2. 《RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control》- 2023
项目网址:https://robotics-transformer2.github.io/
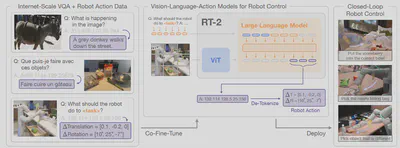
虽然 RT-2 使用与 RT-1 相同的机器人数据进行训练,但 RT-2 将机器人的运动数据转化成了文本 Tokens 输入到模型中一起训练,在输出时这些机器人运动相关的 Tokens 又被去 Token 化为机器人运动数据。这样 RT-2 除了接受文本及视觉信息,还能接受动作信息作为输入,就成了 Vision-Languag-Actio(VLA)大模型。RT-2 模型保留了 VLM 模型的推理能力,又融合了 RT-1 模型对机器人运动的控制能力。
在这篇论文中提到了 VQA 任务,即 Visual Question Answering 任务,这与下文中将提到的 Embodied Question Answering 任务有一定关联。
数据来源:使用现存数据
评估方式:在真实世界进行评估测试。
2.3. 《RT-H: Action Hierarchies Using Language》- 2024
项目网址:https://rt-hierarchy.github.io/
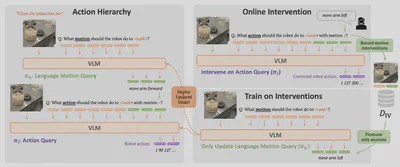
RT-H 提出了运动层级概念(Action Hierarchies),类似于 COT 的概念,在执行任务时先预测需要进行的动作,然后再输入到模型中生成完成动作所需要的运动数据。这样做的一个好处就是可以显示地修正并微调模型,提高了任务执行率和模型训练效率。
2.4. 《Open X-Embodiment: Robotic Learning Datasets and RT-X Models》- 2024
项目网址:https://robotics-transformer-x.github.io/

RT-X 项目的目的旨在整合多家机构的机器人数据,从而构建一个更大规模,具有更强推理即泛化能力的大模型。在此基础上,RT-X 项目诞生了 RT-2-X (55B),迄今为止最大的模型之一,可以在学术实验室中执行更复杂的任务。
2.5. 《OpenVLA: An Open-Source Vision-Language-Action Model》-2024
项目网址:https://openvla.github.io/

OpenVLA 提供了一个开源、轻量化(7B)以及高性能的 VLA 模型,在29个任务及多机器人操作中任务成功率比 RT-2-X (55B) 高出 16.5%。支持在 Open X-Embodiment 数据集上进行训练。
3. 从 Visual Question Answering (VQA) 到 Embodied Question Answering (EQA)
3.1. Visual Question Answering
项目网址:https://visualqa.org/
Visual Question Answering 于 2015 年通过论文《VQA: Visual Question Answering》提出,旨在通过复杂推理来回答有关某一图片的开放式问题。
 |
 |
|---|
3.2. Embodied Question Answering
项目网址:https://embodiedqa.org/
简单的EQA问答:
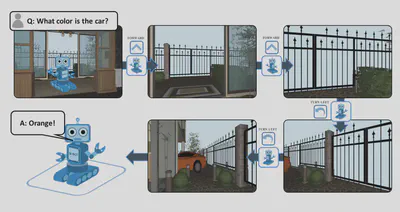
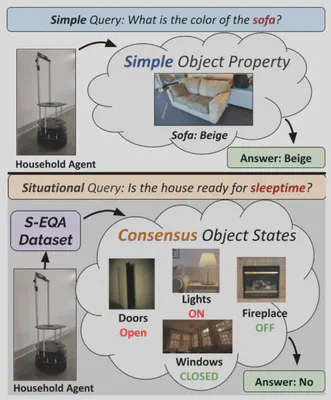
Embodied Question Answering 于 2017 年通过论文《Embodied Question Answering》提出。该任务旨在让代理充分理解环境,以便用自然语言回答有关环境的问题。代理可以通过利用智能眼镜或摄像头所记录的情景记忆,或者通过主动探索环境(如移动机器人)来实现这种理解。
该方向对具身的要求较低,但也有一定门槛。区别于 VQA 只对静态的图像做出反馈,EQA 要求模型能够理解持续的图像输入,通过图像构建对环境的认知,从而对基于环境的问题进行作答。不过由于主流的具身智能研究都覆盖了 VQA 部分,与 EQA 研究也有一定程度上的交叉,所以目前 EQA 领域可以做的研究似乎并不多。下面是我收集的几篇论文:
3.2.1. 《xplore until Confident: Efficient Exploration for Embodied Question Answering》- 2024
项目网址:https://explore-eqa.github.io/
EQA 存在的一个问题是机器人在探索环境来回答问题时,要怎么让机器人知道收集的信息已经足够回答问题并停止对环境的探索,从而提高机器人的工作效率.
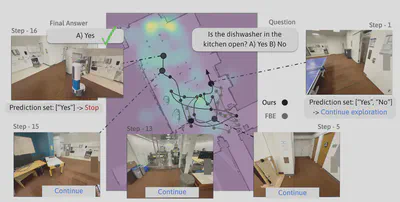
在机器人探索时,机器人会保留一组可能的答案,直到这组答案收敛到单一回答时,机器人就停止探索,任务结束。
3.2.2. 《Embodied Question Answering via Multi-LLM Systems》-2024
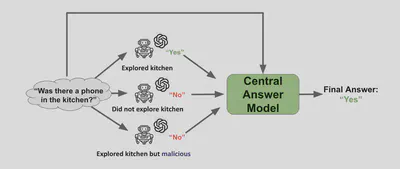
这篇论文主要提出了一个利用多个代理一起探索环境的 EQA 框架,模型会汇总不同代理的回答来给出一个最终的正确答案
4. 学术界的具身智能研究
4.1. 斯坦福大学 - Stanford Vision and Learning Lab (SVL)
组织网站:https://svl.stanford.edu/
4.1.1. 《VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models》-2023
项目网址:https://explore-eqa.github.io/

李飞飞团队提出由于以往的机器人操作都需要先预定义轨迹,其次大规模的机器人获取比较困难,这就导致机器人难以适应复杂场景或环境不断变化的任务。由此 VoxPoser 利用 LLMs 模型提取机器人的操作目标和约束(需要避障的物体),并编写代码发送给 VLMs 模型, VLMs 模型通过视觉感知不断调整代码从而指导机器人完成任务。
该论文开创了一个新的具身智能方向:motion planning(运动规划)。
4.1.2. 《ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation》- 2024
项目网址:https://rekep-robot.github.io/
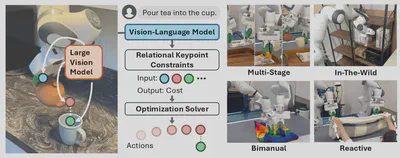
ReKep 算是对 VoxPoser 的改进与延申。在 Relational Keypoint Constraints (ReKep) 中强调了关键点(keypoint)之间的关系与约束。就上述倒水任务,一个 ReKep 首先限制茶壶把手(蓝色)的抓取位置。随后的一个 ReKep 将茶壶嘴(红色)拉向杯口(绿色)的顶部,而另一个 ReKep 则通过将手柄(蓝色)和壶嘴(红色)形成的矢量联系在一起来约束茶壶的预期旋转。
4.2. 斯坦福大学 - Robotics and Embodied Artificial Intelligence Lab (REAL)
组织网站:https://real.stanford.edu/
这个组非常有意思,有很多有趣的研究
4.2.1. 《UMI on Legs: Making Manipulation Policies Mobile with Manipulation-Centric Whole-body Controllers》 -2024
项目网址:https://umi-on-legs.github.io/
该研究提出以任务为中心的数据收集,赋予了机器人手臂末端“鸡头”般的稳定性 - 机械臂末端的位置不会应为机器人自身位置的变化而变化。
该组开发了一个数据收集工具,可以脱离机器人来收集数据,降低了成本。详情参见:https://umi-gripper.github.io/
数据格式参见:https://mani-wav.github.io/
4.2.2. 《Flow as the Cross-domain Manipulation Interface》- 2024
项目网址:https://im-flow-act.github.io/
该项目提出了一种 Im2Flow2Act 的架构,该架构使机器人能够从各种数据源获取操作技能。Im2Flow2Act 包含两个组件:Im2Flow 和 Flow2Act。Im2Flow 在人类演示视频上进行训练,根据任务描述从初始场景图像生成对象流。Flow2Act在模拟机器人数据上进行训练,将生成的对象流(Flow)映射到机器人动作以实现所需的对象运动。
相关论文《Self-Supervised Any-Point Tracking by Contrastive Random Walks》-2024,用来跟踪视频中物体的运动。项目网址:https://www.ayshrv.com/gmrw
4.2.3. 《TidyBot: Personalized Robot Assistance with Large Language Models》 - 2023
项目网址:https://tidybot.cs.princeton.edu/

这项工作研究了使用机器人进行家庭清洁时的个性化问题。在家庭服务中,一个关键的挑战是确定放置每件物品的合适位置,因为人们的喜好可能会因个人品味或文化背景而有很大差异。例如,一个人可能更喜欢将衬衫存放在抽屉里,而另一个人可能更喜欢将它们放在架子上。TidyBot的目标是构建系统,通过先前与特定人的互动,可以从少数几个例子中学习这种偏好。
4.2.4. 《RoboNinja: Learning an Adaptive Cutting Policy for Multi-Material Objects》 - 2023
项目网址:https://roboninja.cs.columbia.edu/
用来自适应切水果的,用来提高果肉出肉率
4.2.5. 《DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset》 - 2024
项目网址:https://droid-dataset.github.io/
DROID 是一个大规模机器人数据集
更多项目请参加该组织网站
5. 创新方向的疑问
5.1. 创建一个新的具身智能方向
类似于从 VQA 过渡到 EQA 研究,我们利用现有研究成果,探寻结合具身场景的新研究方向。该路径一个难点是缺少机器人等硬件支持,难以实验和收集数据。可能的思路是利用现有数据,整合现有技术,提出新的场景问题,创建新的研究方向。
5.2. 在现有方向上进行改进
目前有待改进的研究方向:
- 提升模型的泛化能力。例如,即使折叠的手臂轨迹与拾放任务相似,在拾放任务中训练出来的策略也无法推广到折叠任务中。
- 提升模型的长周期任务执行能力(Long-Horizon Task Execution)。单个指令通常可以转化为机器人的长期任务,如 “打扫房间 “指令,其中涉及重新摆放物品、扫地、擦桌子等。要成功执行此类任务,机器人需要在较长的时间跨度内规划并执行一系列低级动作。
- 增加模型对机器人的控制能力。目前的研究大多只关注机械臂末端的位置及姿态,但不关注机械臂运动过程中的手臂的整体姿态。在面对复杂环境或复杂任务时,可能需要机械臂以某种姿态完成任务,如在有障碍物遮挡或者狭小环境下,需要机械臂进行避障或者以某一特定姿态进行运作。但目前的数据似乎并没有包含机械臂的关节数据,所以该方向的可行性有待商议。
如何评估研究结果: 目前的研究大多使用机械臂在真实世界中来执行任务,用以评估对比研究的结果。我们要进行相关研究的话,或许至少也得上个仿真平台。
6. 附录
6.1. 机器人运动数据解释
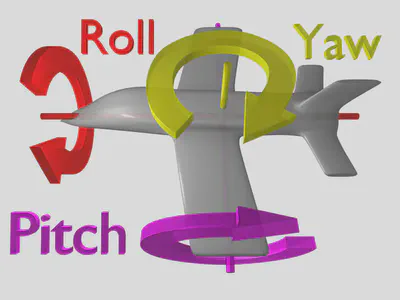 |
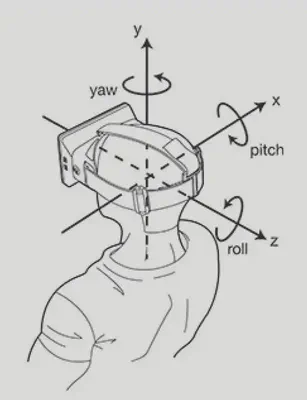 |
|---|
| pitch | yaw | roll |
|---|---|---|
 |
 |
 |
6.2. 具身智能论文汇总
网址:https://github.com/HCPLab-SYSU/Embodied_AI_Paper_List
6.3. 仿真平台
6.3.1. VREP
网址:https://www.coppeliarobotics.com/
一款机器人仿真平台,教育版本免费
操作示例:https://blog.csdn.net/lllxxq141592654/article/details/86678581
6.3.2. VirtualHome
网址:http://virtual-home.org/
VirtualHome 是一个多代理平台,用于模拟家庭活动。代理表示为人形头像,它们可以通过高级指令与环境交互。您可以使用 VirtualHome 渲染人类活动的视频,或训练代理执行复杂的任务。